
There's a right way to be wrong
How to make predictions that are actually useful to the business (incl. 4 real-life examples)

👋 Hi, it’s Torsten. Every week I share actionable advice, frameworks and guides to help you grow your career and business based on operating experience at companies like Uber, Meta and Rippling. Check out the most popular past posts here.
One day, my mother had vision problems in her left eye and went to the doctor. The doctor did a quick examination and concluded there was nothing wrong; the eyes were just getting worse with old age.
Shortly after, the symptoms got worse and my mom got a second opinion. Turns out she had a retinal detachment, and the delay in treatment caused permanent damage.
People make mistakes at work all the time; you can’t be right in 100% of the cases. But some mistakes are costlier than others and we need to account for that.
If the doctor had said “there might be something there” and sent my mother for further tests, there would have been a chance they all come back negative and it’s nothing after all. But the cost of being wrong in that case would have only been a waste of time and some medical resources, not permanent damage to an organ.
The medical field is an extreme example, but the same logic applies in jobs like Data Science, BizOps, Marketing or Product as well:
We should take the consequences, or cost, of being wrong into account when making predictions.
For example, if you work at Uber and are trying to predict demand (which you’re never going to do 100% accurately), would you rather end up with too many or too few drivers in the marketplace?
Unfortunately, in my experience, these conversations between business stakeholders and data scientists rarely happen. Let’s try to change that.
In this post, I will cover:
The different ways we make wrong predictions
How to make sure you are wrong the “right” way
4 Real-life examples to get you thinking about how you want to be wrong
The different ways we are wrong
When we make predictions, we are typically either trying to:
Predict a category or outcome (e.g. users that will churn vs. those that won’t); this is called “classification”
Forecast a number (e.g. sales for the next year)
Let’s look at what it means to be right or wrong in each case.
Predicting a category or outcome
In a so-called classification problem, being wrong means we assign the wrong label to something. For simplicity, we are going to focus on problems with only two possible outcomes (binary classification).
For example, let’s say we’re trying to predict whether a prospect is going to buy from us. There are four outcomes:
We predict a prospect will buy, and they do (True Positive)
We predict a prospect will buy, but they don’t (False Positive)
We predict they won’t buy, but they do (False Negative)
We predict they won’t buy, and they don’t (True Negative)
#2 (False Positive) and #3 (False Negative) are the two ways we can be wrong.
We can put our predictions into a so-called Error Matrix (or Confusion Matrix) to see how we did:

There are three important metrics that help us understand how often, and in what way, we were wrong:
Our Accuracy tells us how many predictions overall were correct; it is calculated as the sum of our correct predictions (True Positives + True Negatives) divided by the total number of predictions
Our Precision tells us how many of our positive predictions were correct. I.e. out of all prospects we said would buy from us, how many actually did? It is the number of True Positives divided by all positive predictions (True Positives + False Positives)
Our Recall tells us how many of the relevant outcomes we correctly predicted, or in other words, how sensitive our model is. I.e. out of all prospects that ended up buying from us, how many did we identify in our prediction? It is calculated as True Positives divided by True Positives plus False Negatives
So now you have three different measures telling you how accurate your prediction is. Which one should you optimize for?
We will get to that in a second.
Forecasting a number
When we’re forecasting a number like sales, it’s a bit simpler. Our forecast is either above or below the actual number (or on target — just kidding, that one never happens 😭).
There are different ways you can measure the accuracy of your forecast here; the most popular ways are likely the Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE).

The problem: By default, these measures of accuracy treat over-forecasting and under-forecasting as equally bad. In reality, that’s rarely the case, though:
For example, if you’re forecasting inventory needs it’s very different to over-predict (and have a few too many items in the warehouse) than to under-predict (and run out of stock, costing you valuable sales).
The key question here is: For the business use case you are trying to forecast, would you rather be too high or too low?
How to ensure you are wrong the “right” way
Just because a prediction model has good accuracy doesn’t mean it’s doing a good job at what you want it to do.
Here’s a real example I’ve encountered to illustrate this point:
Let’s say you work in Marketing or Sales and want to predict which leads will result in successful deals. You train a simple model on historical data and can’t believe your eyes. 90% accuracy! On the first try!
But then you look at the results in more detail and see the following:

Our accuracy is 90%, but the model failed to identify any of the deals that ultimately turned into won customers. Because the majority of leads never convert, the model can achieve high accuracy by simply predicting that not a single lead will convert.
Similarly, you might have a forecasting model for predicting inventory needs that looks pretty good on paper as it has a fairly high accuracy. But if you look more closely, you notice that it almost always slightly under-predicts and your stores run out of inventory at the end of the day as a result.
Obviously, models like that are not very useful.
There are two main challenges you face when making these types of predictions:
Your forecasting model doesn’t have business context; i.e. if you don’t explicitly tell it, the model doesn’t “know” the cost of being wrong one way or the other
In classification problems, the events we want to predict are often rare

The good news is that you can address both issues.
If you are on the Business or Product side, this is a great opportunity to get closer to the work of your Data Science counterparts; and if you’re a DS, this is one of those situations where business context is absolutely crucial to delivering a useful analysis.
Step 1: Understanding the cost of being wrong
The first step in making a prediction model cost-aware is to understand that cost.
Here are some of the key types of costs to consider:
Direct costs: In many cases, a wrong prediction directly causes a financial cost to the business. For example, if a company fails to identify a fraudulent transaction, they might have to eat the resulting costs.
Opportunity cost: If your predictions are wrong, you are often not using your resources efficiently. For example, if you predict a very high volume of support tickets and staff accordingly, your support agents will be idle when fewer tickets come in than you forecasted.
Lost revenue: A misclassification or other wrong prediction can cause you to miss sales. For example, you decide not to send a promotion to a customer because your model predicted they wouldn’t be interested, but in reality they would have made a purchase if they had gotten the promotional email.
Unsubscribes & churn: On the flip side, there are plenty of scenarios where a wrong prediction can annoy users or customers and cause them to churn. Sticking with the above example, if you send too many emails or push notifications because you think users might be interested in these promotions, they might unsubscribe from these comms channels or even churn.
You can have multiple types of cost (e.g. direct costs and lost revenue) at the same time.
Add up all of the applicable individual cost factors to determine the total cost of being wrong in a certain scenario (i.e. a False Positive or False Negative in classification or over- and under-predicting when forecasting a number).
Step 2: Making your prediction model “cost-aware”
Classification (predicting a category or outcome)
Once you have calculated the cost of each type of error (False Positive & False Negative), you can calculate the expected total cost of being wrong for your forecasting model.
You get this overall cost by multiplying the likelihood of each type of error with the cost of that type of error and summing it all up:

Mathematically, your goal should be to minimize this overall cost. But to do this, you need to make sure your prediction model actually takes this cost into account.
There are many ways to make your classification model cost aware, but I’m going to cover the three main ones I find most useful in practice:
1. Adjusting the classification threshold
Many classification models like Logistic Regression don’t actually output a classification, but rather a probability of an event occurring (so-called probabilistic models).
So sticking with the previous example, if you’re predicting which transactions are fraudulent, the model doesn’t actually directly say “this is a fraud transaction”, but rather “this transaction has a [X%] probability of being fraud”.
In a second step, the transactions are then put into two buckets based on their probability:
Bucket 1: Fraudulent transactions
Bucket 2: Regular (non-fraudulent) transactions
By default, the threshold is 50%; so all the transactions with a probability > 50% are going into Bucket 1, the rest into Bucket 2.
However, you can change this threshold. For example, you could decide a 20% probability is enough that you want to flag a transaction as fraud.
Why would you do this?
It goes back to the cost of being wrong. Missing a fraudulent transaction is much more costly to the company than flagging a transaction as fraud that turns out to be fine; in the latter case, you just have minor costs of an additional manual review by a human and a delay in the transaction which might annoy the customer.
How do you decide which threshold to choose?
You have two options:
Option 1: Use the Precision-Recall Curve
The so-called Precision-Recall Curve shows you the Precision (how many of our positive predictions were correct) and Recall (how many relevant outcomes we successfully identified) at different thresholds.
It’s a trade-off: The more fraudulent transactions you want to detect (higher Recall), the more false alarms you’ll have (lower Precision). You can align with your business partners on a point on the curve that you are comfortable with. For example, they might have a minimum share of fraudulent transactions they want to catch.
To make sure your choice is reasonable, you can then calculate the total cost of being wrong for your chosen point per the formula at the beginning of this chapter.

Option 2: Calculate the cost-minimizing threshold
Based on the cost of a False Positive and False Negative, you can calculate the threshold that minimizes the overall cost.
For a well-calibrated model, this is:

An example:
If your cost of a False Negative (e.g. failing to identify a fraudulent transaction) is $9 and that of a False Positive (e.g. falsely flagging a transaction as fraud) is $1, then the Ideal Threshold would be 1 / (9 + 1) = 1 / 10 = 0.1.
So even if the chance that something is fraud is only slightly above 10%, you would want to flag the transaction and have a human review it.
2. Rebalancing your training dataset
As mentioned above, the event we’re trying to predict is often underrepresented in the data that we’re training our model on (these events are called the “minority class”).
At the same time, failing to identify these events usually has a very high cost to the business.
A few examples:
We try to predict which users will churn in the next X days, but few users actually churn in a given timeframe
You predict whether a certain transaction is fraudulent or not, but fraud is the absolute exception
We try to predict whether there are signs of cancer on scan, but most patients are healthy
Failing to detect these rare events is typically very costly, but most models struggle to perform well with such imbalanced datasets. They simply don’t have enough examples to learn from.
To deal with this issue, you can oversample the examples of the underrepresented class so that the positive events are more equally represented. In plain English: You are creating more instances of the rare event so that the model has an easier time training to detect them.
You either do this by duplicating existing examples of the minority class in your training data set, or by creating synthetic ones.
Alternatively, you could also reduce instances of the majority class to balance things out (undersampling) Both oversampling and undersampling come with challenges, which are beyond the scope of this article. I linked some resources for further reading at the end.

How do you rebalance your dataset to minimize the cost of being wrong?
If your classifier is using a standard threshold of 0.5, you can calculate by what factor you need to multiply the number of majority examples with the following formula:
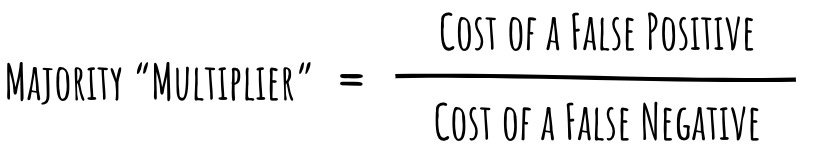
An example:
So using the same values as in the example above ($1 cost of falsely flagging a transaction as fraud, $9 cost of missing a fraudulent transaction), the factor would be 1 / 9 = 0.1111.
In other words, we would scale down the number of majority examples in the training set by a factor of 9 (undersampling).
3. Modifying the weights for each class
Many machine learning models allow you to adjust the weights assigned to each class.
What does that do? Let’s say again we’re predicting fraudulent transactions in our app. Our model tries to minimize misclassifications. By default, failing to identify fraud and falsely flagging a normal transaction as fraud are treated as equally bad.
If we assign a higher weight to the minority class (our fraudulent transactions) though, we essentially make mistakes in this class (i.e. failing to identify fraud) more costly and thus incentivize the model to make fewer of them.
Forecasting a number
We’ve talked a lot about how you can make your classification model cost-aware, but not all predictions are classifications.
What if you’re forecasting how much inventory you need or how many organic leads you expect for your Sales team? Forecasting too high or too low in these scenarios has very different consequences for the business, but as discussed earlier, most widely-used forecasting methods ignore this business context.
Enter: Quantile Forecasts.
Traditional forecasts typically try to provide a “best estimate” that minimizes the overall forecast error. Quantile Forecasts, on the other hand, allow you to define how “conservative” you want to be.
The “quantile” you choose represents the probability that the actual value will land below the forecasted value. For example, if you want to be sure that you don’t under-predict, you can forecast at the 90th percentile, and the actual value is expected to be lower than your forecast 90% of the time.
In other words, you are assigning a higher cost to under-forecasting compared to over-forecasting.
4 real-life examples
That was a lot of theory; let’s put it into practice.
Here are some real-life scenarios in which you’ll have to make sure you are picking the “right” way to be wrong.
Example 1: Lead scoring in B2B Marketing & Sales
🤔 The problem:
Type: Predicting an outcome (classification problem)
You work at a B2B SaaS company and want to figure out which leads are going to “close”, i.e. turn into customers. The high-potential leads your model identifies will receive special attention from Sales reps and be targeted with additional Marketing efforts.
💸 The cost of being wrong:
False Positive: If you falsely flag a lead as “high potential”, you are 1) wasting the time of your Sales reps and 2) wasting the money spend on high-touch Marketing campaigns (e.g. gifts).
You can calculate #1 by calculating the average hourly compensation of your Sales reps (total annual cost divided by hours worked) and multiplying it by the average number of hours spent on a (unsuccessful) deal
False Negative: If you fail to identify a high potential lead, you have a lower chance of closing the deal since you’re not deploying your best tactics, leading to lost revenue.
The cost can be calculated as the decrease in win rates for deals if they don’t receive the “high touch” Sales & Marketing experience multiplied with the average contract value of a deal.
⚙️ What to optimize for:
By default, your model will flag very few leads as “high potential” because most leads in the training data never closed.
However, since losing a deal in B2B SaaS is typically much more costly than wasting some resources on working an unsuccessful deal (esp. if you target Mid Market or Enterprise companies with larger deal sizes), you’ll want to tune your model to massively penalize False Negatives.
Example 2: Inventory for a sales promotion
🤔 The problem:
Type: Forecasting a number
You work at an E-Commerce company and want to predict demand for your most important products for a big upcoming event (e.g. Amazon Prime Day).
💸 The cost of being wrong:
Over-forecasting: If you overestimate the demand, you’ll have excess inventory. The cost consists of storage costs in the warehouse, plus you might have to write off the value of the items if you can’t sell them later.
Under-forecasting: If you under-predict the demand, you’ll run out of inventory and miss out on sales. Plus, your reputation will be tarnished as customers value constant availability and reliability in E-Commerce, pot. leading to churn.
⚙️ What to optimize for:
The cost of running out of inventory is much higher than having some excess (non-perishable) stock. As a result, you’ll want to minimize the odds of this happening.
You can use a Quantile Forecast to decide exactly how much inventory risk you’re willing to take:

In this example, if you stock 600 units of your product, there is a 75% chance that you have sufficient inventory for the promotional event.
Example 3: Email promotions
🤔 The problem:
Type: Predicting an outcome (classification problem)
You’re planning to run a new type of Email marketing campaign and are trying to figure out which users you should target.
💸 The cost of being wrong:
False positive: If you opt someone into the campaign and they don’t find it relevant, they might unsubscribe. The cost is that you can’t email them anymore with other campaigns and might lose out on future engagement or sales
False negative: If you don’t opt someone in that would have found the campaign relevant, you are leaving near-term user engagement or sales on the table
As you can see, the trade-off here is between short-term benefits and pot. negative long-term consequences.
⚙️ What to optimize for:
This case is less clear-cut. You would have to quantify the “lifetime value” of being able to email a user and then tune your model so that the expected lost future revenue from unsubscribes equals the expected short-term gains from the email campaign itself.
Example 4: Sales hiring
🤔 The problem:
Type: Forecasting a number
You work in a B2B company. You are launching a new market and are forecasting the expected number of qualified opportunities to figure out how many Sales reps you should hire.
💸 The cost of being wrong:
Over-forecasting: If your forecast is too high, you are hiring more sales reps than you can “feed”. The reps will be unable to hit their quota, morale will tank, and you will eventually have to let people go.
Under-forecasting: If your forecast is too low, you end up with more opportunities per Sales rep than expected. Up to a certain level, this excess volume can be “absorbed” (reps will spend less time on Outbound, managers and reps from other markets can pitch in etc.). Only if you massively under-predicted, you will start leaving money on the table.
⚙️ What to optimize for:
Over-forecasting, and as a result over-hiring, is extremely costly. Since the business has more flexible ways to deal with under-forecasting, you’ll want to choose a Quantile Forecast where the actual deal volume lands above the forecast the majority of the time.
📚 Further reading
Deeper dives on rebalancing your training data:
Model calibration:
Quantile Forecasts:
Further reading on cost-aware machine learning:
🙏 Credits
Thank you to Kartik Singhal and Tessa Xie for thoughtful feedback on a draft of this article.
I just gave your article another read while on my train to the office.
I remember using the error matrix so much while I was doing projects in school, but I rarely do it at work. That’s needs to change.
Thank you for the great read!
Baking cost into error function of the prediction models is crucial as more and more pieces of the puzzles are automated. Really like the 4 real life examples to demonstrate this.